In recent years, git has rapidly been adopted by software developers in the software industry. Initially it was a toy used mainly in open source projects but it is now finding its way into the rest of the software development world. At this point in time, git is emerging as a tool of choice for doing version control for a large group of developers.
A reason for the popularity of git is that it enables a lot of new and different work flows that allow development teams to change the way they deliver software and deliver better software faster.
In this blog post I present some ideas for implementing a git work flow that allows for something else than the centralized work flow that is common for projects with a central subversion repository, like the project I am currently working on, while still keeping the central subversion repository.
Git workflows
Git is a powerful tool that allows people to collaborate in all sorts of ways. Here are some examples of git based work flows that people have come up with:
- The people at GitHub work with feature branches and merges to a stable master that is kept in a releasable state and is continuously deployed to their production servers. They use pull requests to get changes from the feature branches into the master branch. Of course they use their own product for this.
- Git-flow uses different branches for stable releasable code, development, features, and hot fixes. Additionally it has a few rules about how to merge changes between these branches and scripts to support this. Git-flow was developed by a group of developers that were experimenting with different work flows before they settled on what is now known as git-flow.
- Linux kernel development (which is where git originated) uses an email based pull model where git formatted patches are pulled from mailing lists and integrated into the main line trunk after extensive reviews by the kernel maintainer (i.e. Linus Torvalds himself). This works because the review and patch aggregation work is delegated to lieutenants who in turn delegate work to yet more people. Dozens of people are regular contributors and they in turn source commits from an even larger group of people. Effectively, Linux kernel development is a tree of repositories with changes being pulled up all the way to the top where Linus Torvalds sits.
These work flows are optimized for very different goals and circumstances. The GitHub model is optimized for continuous deployment and is very appropriate for any server-side software where time to market is crucial. Git-flow uses a more traditional release model where released code has to be supported (with features and hot fixes) for extended periods of time. Finally, the Linux kernel team has optimized their work flow to scale the development to a massive team size with members distributed world-wide across hundreds of companies. It is one of the largest software projects in the world and the kernel team has sustained a very rapid evolution for years now. Interestingly enough, Linus Torvalds created git to support this.
Using git-svn to pretend we live in a git world
Where I work, we still use a central subversion repository to maintain Nokia’s map search component. For various reasons, migrating from subversion to git is not a priority and technically challenging in our case for various other reasons that are beyond the scope of this post. Several teams commit on this central repository and we have a Jenkins doing CI builds, automated deployments to test machines, etc. We take quality very serious and we have a lot of infrastructure to do QA on both functional and data changes since both tend to have an effect on the user experience.
Several people (me included) across the teams are using git-svn to interact with the central subversion server. This allows us to work locally in git and treat the central svn as a git remote. Using git-svn is quite straight forward: you git svn rebase to get upstream changes from svn and you git svn dcommit to push out your local git commits back to svn. However, we have not really adapted our work flow and our workflow is very similar to traditional svn centric work flows. To learn more about git-svn you can read this tutorial (or any of the several similar tutorials that you may find via Google)
Recently, I have started looking into adopting a more sophisticated work flow for our team and move us away from the highly centralized work flow around the central svn. Because our subversion is a pretty busy place and because our Jenkins machines take hours to churn through our quite extensive system, quality, and deployment test suite (which means there is a significant delay between committing and builds breaking), there tends to be a lot of fallout if svn trunk breaks. Unfortunately, this is a growing concern and teams are often blocked by instability on trunk. To address this, my team wants to adopt a work flow that allows us to accumulate commits, verify that they don’t break anything, etc. and then only when everything looks great, we push out a whole batch of git commits to the central svn repository. All this should be accomplished without disrupting other teams that may opt to continue to use svn the old way.
About rebasing and merging
Unfortunately, git-svn is a bit of a headache when it comes to using the git based work flows I listed above. The main issue is the difference in semantics between a git merge and a svn merge and the resulting lack of a git svn merge operation: you can only rebase with git-svn.
A svn merge applies diffs to files. A git merge combines graphs of commits into a graph that has the commits from both graphs. Git users synchronize by exchanging their changes to this graph. Svn history is linear: each commit has only one ancestor. Git history is a directed acyclic graph (if you use merge) and commits can have several ancestors. Git svn dcommitting a non linear history of commits to svn is impossible/very hard and very easy to get wrong.
Suppose we have a branch with some work
branch E
/
master A--B--C--DA git merge would produce the following graph:
branch ------E
/ \
master A--B--C--D--FThe branch is merged into the master with a special commit F that has D and E as its ancestors. In case of conflicts, the resolution to those conflicts is part of F as well. If you read the articles on the git work flows I linked above, you’ll learn that merging like this is very common in the git world. Unfortunately, svn merges work quite different and it is not possible/recommended to git svn dcommit non linear commit graphs.
A git rebase on the other hand would produce a different history:
branch E
/
master A--B--E--C--DNote there is no F commit. Basically it rewinds the changes on the master until B, applies the commit from the branch (E), and then re-applies the remaining commits that were on the master. History gets rewritten. When you do a git svn rebase, it does exactly the same: rewind the local git commits, apply the upstream svn commits, and then reapply the local git commits. This allows you to git svn dcommit your commits without conflicts.
Limitations of git-svn
Of the three work flows I listed at the beginning of this post, two heavily depend on using git merges. So, you can’t use them with git-svn. The Linux kernel model relies on exchanging patches via email. This works fine in a git-svn world but is kind of tedious in a team that is neither distributed geographically nor particularly large.
Additionally, git-svn in combination with git or svn branches and a git remote for sharing code with team members is a bit fragile. It is easy to get wrong and push commits that do a lot of unintended things. Whenever you update from svn using git svn rebase, you rewrite your local git history. The commits in the git repository are re-ordered so that your local git commits appear after the svn commits. This allows you to dcommit them back to svn. Rewriting history like this is fine as long as your local git repository is the only one affected. However, if you start sharing your local commits via a central git repository, you need to be very careful. Particularly, you may end up reordering commits that are already in svn with local commits. Dcommitting such a rewritten history could have bad effects.
However, a git based work flow with multiple people by definition involves multiple git repositories: at least one for each person, remote git repositories, and even Jenkins has its own repository. To synchronize between those repositories commits have to be pushed or pulled between them in some way. Since neither git merge or rebase are safe to use in combination with git-svn, this poses a bit of a dilemma.
Coming up with a decentralized git-svn work flow that doesn’t suck
Both rebases and merges are problematic. One rewrites history that should not be rewritten (e.g. mixing svn commits and git commits) and the other one creates history that is not compatible with subversion. Luckily, there are more ways to share commits in the git world.
Git format-patch is used in the Linux git work flow to integrate changes into the Linux kernel source tree. It allows people to email git commits to each other and to apply the commits one by one to a compatible git repository with a shared history using the git am command.
This may seem primitive but it is actually very different from simply using diff and patch like you might be used to in the svn world. Git format-patch exports the commit, including its commit message, relation to previous commits, commit hash, and other metadata. It is for all practical purposes a commit, not merely a patch. Git am then re-integrates the commit into another repository. It’s like the commit was pulled but without the need for a direct link between the repositories. In case of conflicts, you can easily modify the commit.
The git-svn work flow
The work flow I’m about to outline is something that I want our team to start using. It has not been battle tested yet but I’ve done a lot of research on the topic so far and I feel this is something that might actually work. It uses git format-patch and git am to apply changes to branches and uses a central repository to give everybody easy access to the change sets on different branches.
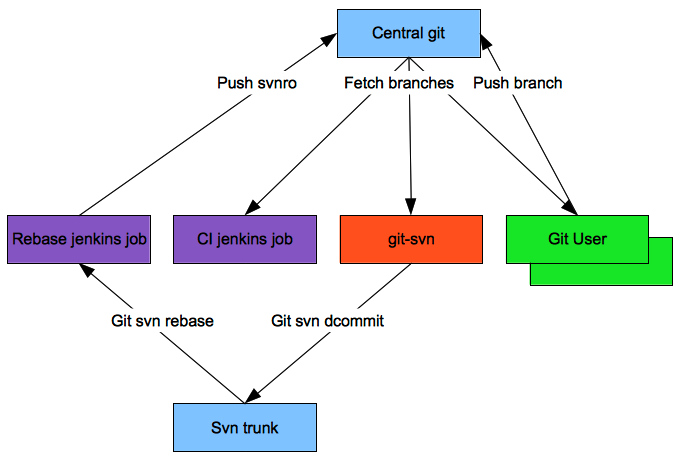 The image above outlines
the general layout. The green boxes are git
users working on their local git repositories.
The two blue boxes are a central svn and git
repository. The purple boxes are jenkins jobs
and finally we have a special repository that
has the central git as it’s remote and the
subversion repository as another remote.
The image above outlines
the general layout. The green boxes are git
users working on their local git repositories.
The two blue boxes are a central svn and git
repository. The purple boxes are jenkins jobs
and finally we have a special repository that
has the central git as it’s remote and the
subversion repository as another remote.
- The central git server is used to store change sets in separate git branches. The reason we want a central git server is twofold. 1) We want our changesets backed up in a safe place and allow all team members to access them. 2) We want continuous integration for all our branches and that’s just a whole lot easier if you are dealing with only one central repository.
- One of these branches is automatically populated with changes from svn by a jenkins job that regularly git svn rebases a local repository and then pushes the new svn commits from upstream to this branch on the central repository. This branch is called svnro. The main point of this is to isolate the interaction with svn (and the associated fragility) and allow all git users to simply rebase against a git branch rather than having to use git-svn directly.
- There is no master branch in the central repository. The svnro branch is the closest thing to it but as the name implies, it is read-only (except for the jenkins job).
- Team members create branches from svnro and commit their work on the branch and then push that branch to the central git repository. Each branch has an owner and that owner is the only one that modifies the branch.
- If another team member wants contribute to a branch, they should create a new branch from svn ro and then use git format-patch and git am to apply changes from the other branch. Then they should do their changes on that branch and when done ask the owner of the other branch to integrate their changes using git-format patch. This emulates the fork + pull request model popularized by Git-Hub.
- Branch owners regularly rebase their branch against svnro to ensure that their change set is compatible with upstream svn changes. Because all branches on the central git repository are read only (except for their owner), it is alright for the branch owner to rewrite history like this and push the rewritten history to the central git repository. Git will disallow this by default and this only works if you use a git push –force.
- Rebasing or merging between other branches on the central repository is not allowed to avoid accidentally mixing svn commits with new commits. The only exception to this rule is svnro. Since rebases and merges can wreak havoc on a svn repository it is best to not use them at all.
- Because branch owners rewrite history of their branches every time they rebase against svnro, it is important for other team members to not commit that branch. Failing to observe this rule may mean commits are lost when the owner rebases against svnro and then pushes the branch. As soon as somebody with local commits pulls that change, all local commits are lost! Likewise a rebase against svro followed by a git push –force will actually wipe out other people’s commits on the central repository. This is why branches must have owners.
- Ownership of a branch may be transferred of course. Team members should communicate about this clearly to avoid losing commits. In practice, two team members can work on the same branch as long as they carefully coordinate their updates, commits, and rebases against svnro.
- A Jenkins continuous integration build tests every branch in the central repository. This is quite easy to set up using the git support in Jenkins. This ensures each feature branch has continuous integration before we git svn dcommit.
- When ready, changes on a branch can exported using git format-patch and applied to the master of a git-svn clone and git svn dcommitted (the orange box in the diagram).
- The person doing a svn dcommit must make sure the history is free of merges and has been properly rebased against svn trunk (i.e. all svn commits must appear before the new git commits).
- Before dcommitting, all change sets must pass all available tests. Because we can group large change sets and test them in one go, we can afford to invest time in this. Pushing untested change to svn is risky and should be avoided.
- A dcommit is a great opportunity for code reviews and eyeballing commits and should be handed off to a different person than the feature branch owner with the changes.
The model I outlined here combines the Linux kernel and Git-Hub model. Changes are pulled between branches like in Git Hub using the format-patch method. A feature owner applies changes from other team members to integrate them, thus taking a similar role as a lieutenant in the Linux Kernel world. Finally, whomever does the git svn dcommit gets to play Linus Torvalds.
Example
As an example, we’ll run through a scenario and review the state of the various git branches in the central git repository, the git-svn clone of trunk and svn.
Step 1: create a branch and do some work
branch1 x--x--x
/
|
svnro *--*
git-svn *--*
trunk *--*Two commits from svn are pushed onto svnro in central. Somebody creates a branch and does some work.
The owner of branch1 does something like:
git fetch origin
git checkout svnro
git checkout -b branch1
...
git commit -m 'work'
git push branch1Step 2: create another branch and do more work
branch2 x--x--x--y--y
/
|
branch1 x--x--x |
/ |
| |
svnro *--*--*--*--*--*
git-svn *--*--*--*--*--*
svn trunk *--*--*--*--*--*Another user creates a branch applies the changes from branch1 and commits some additional changes. Meanwhile several commits have happened in svn and both branches are slightly behind now.
The owner of branch2 does something like
git fetch origin
git checkout branch
git format-patch -n -3
git checkout svnro
git checkout -b branch2
git am *patch
...
git commit -m'work'
git push branch2Step 3: apply the new work from branch2 on branch1 and do more work
branch2 x--x--x--y--y
/
|
branch1 | x--x--x--y--y--z
| /
| |
svnro *--*--*--*--*--*--*--*--*
git-svn *--*--*--*--*--*--*--*--*
svn trunk *--*--*--*--*--*--*--*--*The owner of branch1 rebases against svnro and applies changes from branch2 and does an additional commit.
git fetch
git checkout branch2
git format-patch -n -2
git checkout branch1
git am *patch
git rebase svnro
...
git commit -m 'work'
git push branch1 --forceStep 4: dcommit the change and remove the branches
svnro *--*--*--*--*--*--*--*--*
git-svn *--*--*--*--*--*--*--*--*--*--x--x--x--y--y--z
svn trunk *--*--*--*--*--*--*--*--*--*--x--x--x--y--y--zBranch1 and branch2 are deleted and someone applies the changes on branch1 on the git-svn master, tests, and then dcommits to trunk.
git fetch origin
git checkout branch
git format-patch -N -6
git checkout master
git svn rebase
git am *patch
# build and test
git svn dcommit
git push :branch2
git push :bramch1Summary
The above method works fine. We have manually collaborated on a couple of change sets following this process. Git is a very powerful tool and there are many variations that one can experiment with and that may work equally well. Also git has loads of additional options to manipulate commits that I haven’t really explored yet. Despite using it for a couple of years, I’ve barely scratched the surface of its feature set, which is quite extensive. I’m by no means an expert user.
The above work-flow provides us with something that is doable, relatively risk and pain free, and useful. It allows my team to perfect new features and changes in a central git repository, benefit from CI builds, and allows us to treat svn as a stable branch, which is what we are after here.
I’m planning to start setting up infrastructure to support this process in the next few months. This includes setting up a jenkins, a centrally provisioned git repository that we can rely on (we have great git infrastructure in Nokia), and scripts to automate some of the more tedious things.
This work flow is by no means the final or only answer to the problem I outlined. I’ll probably improve the process as I implement it and gain some experience with it; come up with better/smarter ways to use git; etc. If you have suggestions, comments, or corrections for the above, they are more than welcome. Please leave a comment or contact me directly.